UniSep
UniSep: Universal Target Audio Separation with Language Models at Scale
Abstract
We propose Universal target audio Separation (UniSep), addressing the separation task on arbitrary mixtures of different types of audio. Distinguished from previous studies, UniSep is performed on unlimited source domains and unlimited source numbers. Amid the rapid expansion of the modeling space, a large language model (LLM) is deployed by predicting next token conditioned on the universal mixtures, leveraging the power of LLM in handling complex tasks with large-scale data. Moreover, a novel pre-training strategy is proposed to utilize large-scale audio data, which reduces the efforts of large-scale data simulation. We demonstrate the effectiveness of scaling dataset in an audio separation task: we use large-scale data (36.5k hours), including speech, music and sound, to train a universal target audio separation model that is not limited to a specific domain. Experiments indicate that separated samples show competitive subjective evaluation results compared with single-task models.
Method
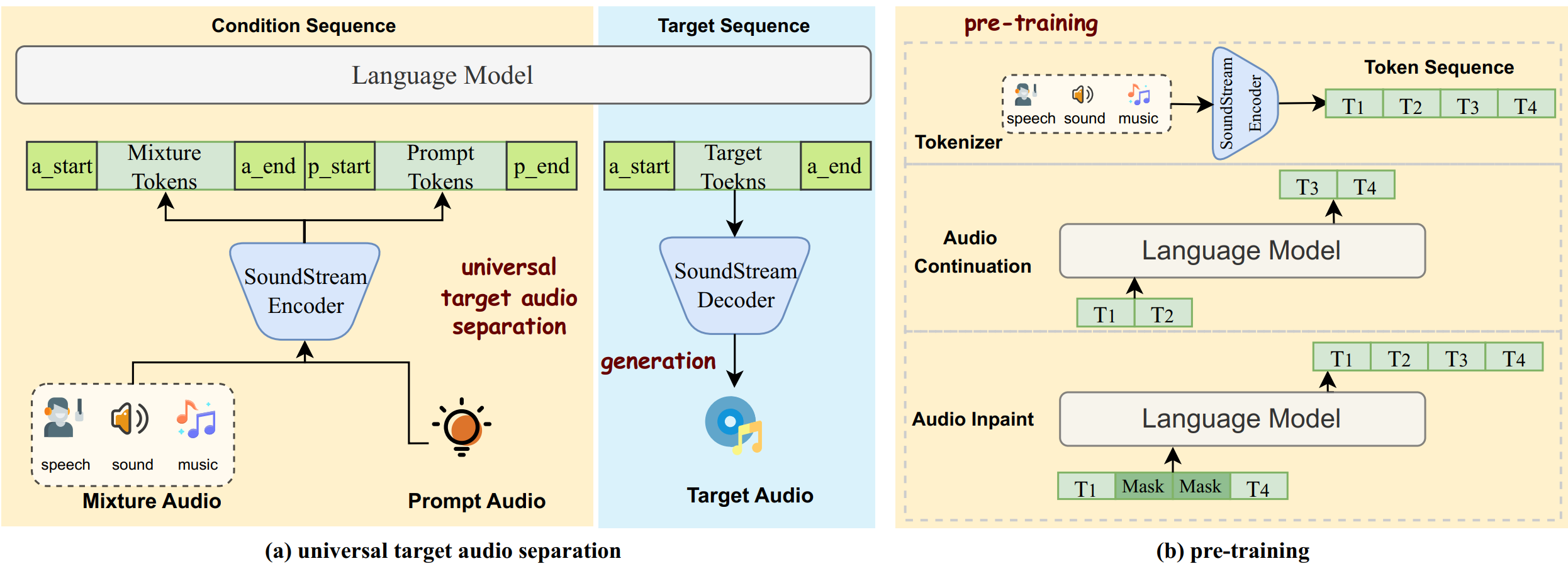 In the following, we will present some samples generated using our proposed UniSep.
In the following, we will present some samples generated using our proposed UniSep.
Target Speaker Extraction / Target Speech Separation
We should not only focus on the timbre, but also ensure the correctness of the speech content.
 |
 |
 |
 |
 |
||
 |
 |
 |
 |
 |
||
Target Sound Separation
AudioSet
ESC-50
Target Music Separation
Downstream Task: language-queried audio source separation
Our trained UniSep can be fine-tuned using a small amount of data to accomplish other tasks, e.g. language-queried audio source separation task. We show that UniSep can be fine-tuned on text-audio pairs, and then it can be used to separate audio based on text description. We utilize T5 to encode the text description. In the table below, the text description comprises two audio descriptions that form the mixed audio. The red font highlights the target audio description we aim to extract from it.
“UniSep+Fine-tuning” represents fine-tuning on our UniSep model. ‘LASS’ is from the “Separate what you describe: Language-queried audio source separation” model. ‘AudioSep’ is from the “Separate Anything You Describe” model.
Please note that AudioSep is trained on a massive dataset of 14,000 hours of audio-text pairs, including AudioSet, VGGSound, AudioCaps, Clotho v2, and WavCaps. In contrast, our UniSep is fine-tuned on a much smaller dataset of only around 16.7 hours from the AudioCaps dataset. Despite being fine-tuned on a considerably smaller dataset, UniSep can still achieve competitive results in audio separation tasks. This demonstrates UniSep’s potential for fine-tuning on a smaller dataset to achieve competitive performance in audio separation tasks.
 |
' Typing on a computer keyboard ' + ‘ The rain pours, and a man talks ‘ |  |
 |
 |
 |
 |
' Several bells ringing ' + ‘ A woman talks, followed by the laughter of a crowd in the background, followed by a woman talking ‘ |  |
 |
 |
 |
 |
' Rain and lighting during a storm pouring down ' |  |
 |
 |
 |
 |
' Someone is typing on a keyboard ' |  |
 |
 |
 |
 |
' A woman giving a speech ' |  |
 |
 |
 |